Суть
Компания Anthropic представила BioMysteryBench — новый бенчмарк для оценки способностей больших языковых моделей (LLM) в области биоинформатики. Инициатива направлена на решение фундаментальной проблемы ИИ-индустрии: как объективно измерить способность нейросетей проводить реальные научные исследования, а не просто сдавать стандартизированные экзамены.
Контекст
На ранних этапах развития языковых моделей их возможности оценивали с помощью тестов, имитирующих человеческие экзамены. Бенчмарки вроде MMLU или GPQA проверяли экспертные знания и способность к логическому выводу. Позже появились более сложные тесты, такие как LAB-Bench или SciGym, которые пытались симулировать лабораторную среду.
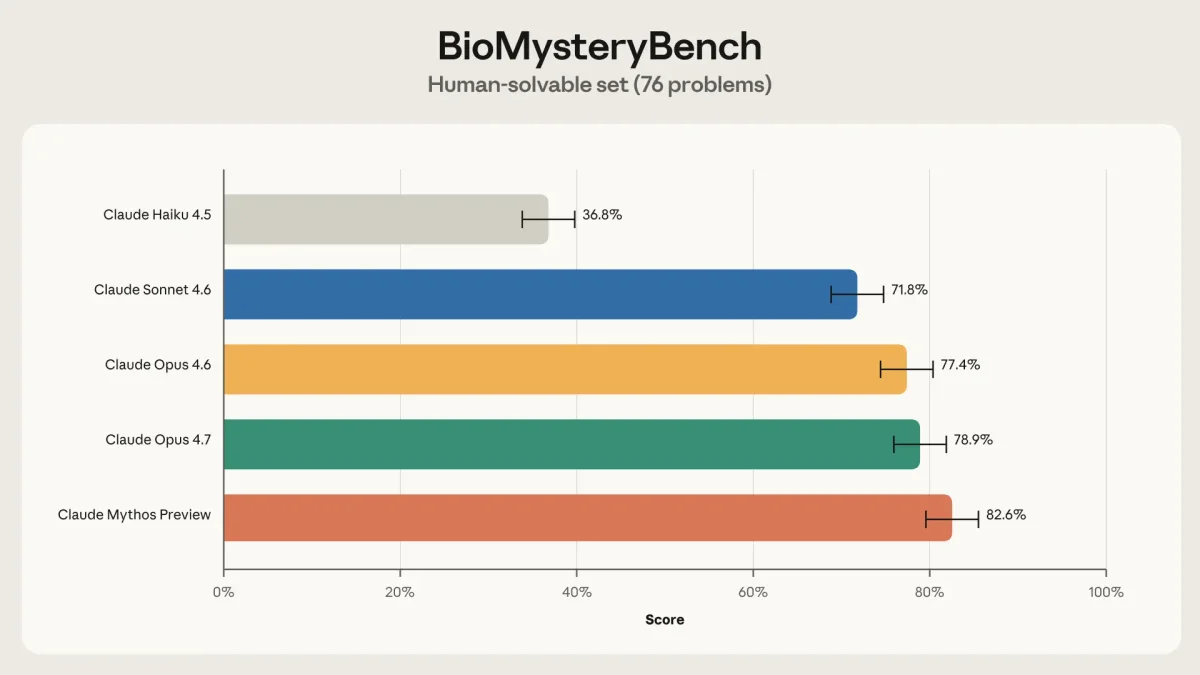
Graph of accuracy on human-solvable problems
Однако настоящая наука устроена иначе. Исследовательская работа в биологии требует чтения научных статей, запросов к базам данных, написания кода и анализа зашумленных наборов данных. Кроме того, оценка научных результатов сталкивается с тремя проблемами. Во-первых, в биологии существует множество правильных способов решения одной и той же задачи. Во-вторых, индивидуальные решения ученых субъективны и могут приводить к разным выводам при работе с одними и теми же данными. В-третьих, самые важные вопросы — это те, на которые у человечества пока нет ответов.
Детали
BioMysteryBench включает 99 вопросов из различных областей биоинформатики, составленных профильными экспертами. Главная особенность бенчмарка заключается в его архитектуре:
- Модель получает задачу и помещается в изолированную среду с базовым набором инструментов биоинформатика.
- ИИ имеет право устанавливать дополнительные библиотеки (через pip или conda) и обращаться к каноничным базам данных (NCBI, Ensembl).
- Оценка производится исключительно по финальному ответу, который имеет объективное подтверждение в реальности (например, определение организма по кристаллической структуре), а не по шагам, которые модель предприняла для его получения.
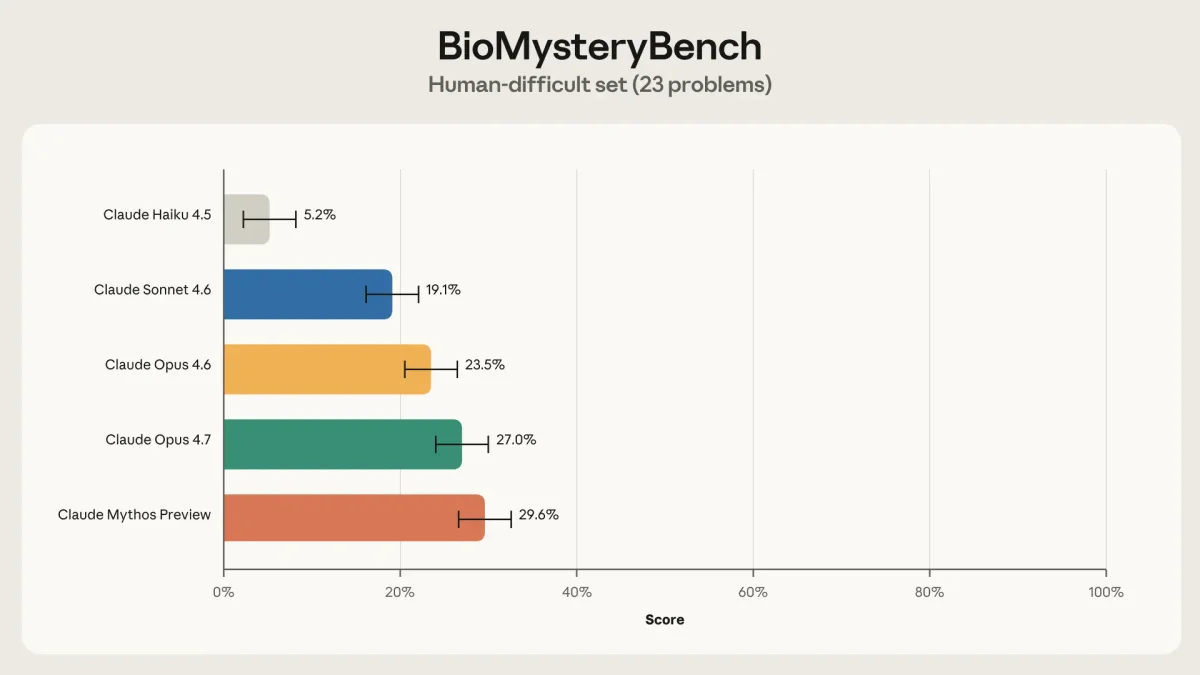
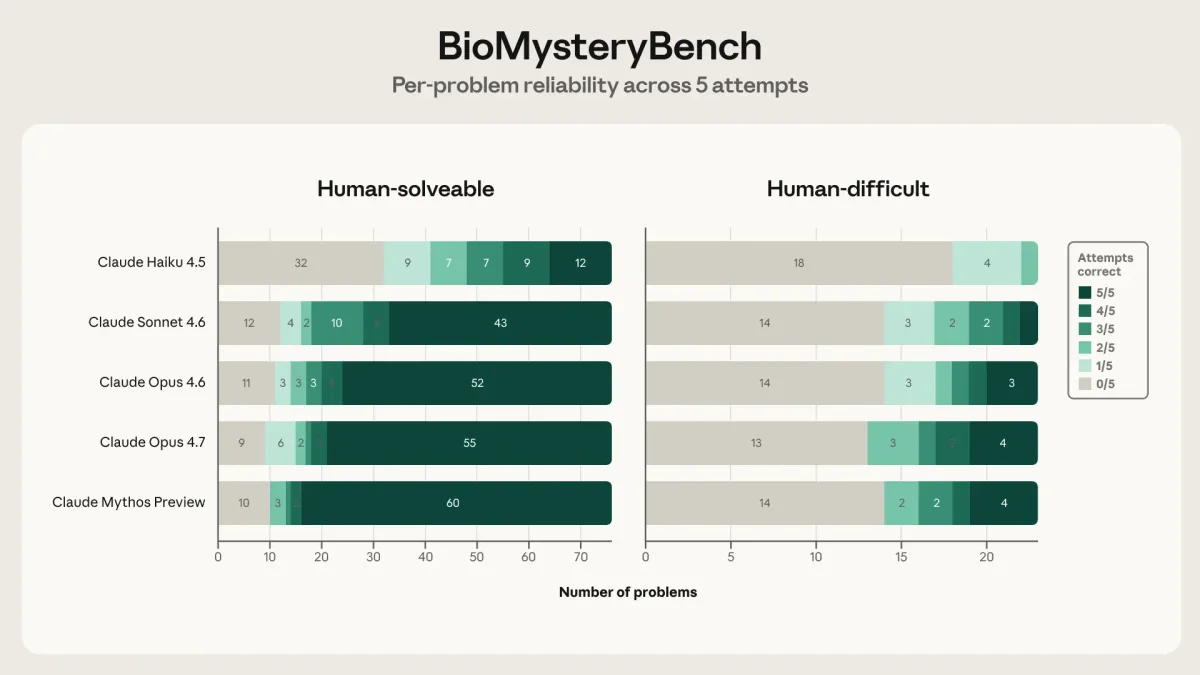
По данным Anthropic, текущие поколения моделей показывают результаты на уровне экспертов-людей. Более того, последние версии Claude смогли решить ряд задач, с которыми не справилась контрольная группа специалистов, используя при этом совершенно иные аналитические стратегии.
Graph showing performance on human-difficult problems
Анализ
Подход Anthropic решает критическую проблему предвзятости в оценке ИИ. Традиционные бенчмарки часто наказывают модель, если ее ход мыслей не совпадает с человеческим, даже если итоговый вывод верен. BioMysteryBench дает системе свободу выбора метода.
Это означает, что индустрия переходит от оценки моделей как «энциклопедий» к их оценке как «научных агентов». Способность ИИ находить нестандартные пути решения в сложных и зашумленных данных открывает новые возможности для анализа геномов, поиска биомаркеров и разработки лекарств.
Перспектива
Успешное применение агентных бенчмарков вроде BioMysteryBench ускорит интеграцию ИИ в реальные лабораторные процессы. В краткосрочной перспективе мы увидим больше автономных систем, способных брать на себя рутинный анализ данных. В долгосрочной — модели начнут предлагать гипотезы и выявлять закономерности, которые упускают человеческие исследовательские группы из-за когнитивных искажений или нехватки вычислительных ресурсов.