Google анонсировала выпуск Gemini 3.1 Flash TTS — нового поколения моделей для синтеза речи (Text-to-Speech). Главным нововведением стала не только улучшенная естественность звучания, но и внедрение системы звуковых тегов (audio tags), которая позволяет разработчикам управлять генерацией голоса с режиссерской точностью.
Долгое время на рынке ИИ-синтеза речи доминировали решения, которые выдавали качественный, но слабо контролируемый результат. Разработчикам часто приходилось полагаться на случайность или перегенерировать аудио десятки раз, чтобы добиться нужной интонации для конкретного слова. С выходом Gemini 3.1 Flash TTS фокус смещается от простой озвучки текста к созданию полноценных и управляемых аудиосцен.
Gemini logo next to the text "3.1 Flash TTS", all over colored dots
Ключевая техническая особенность новой модели — гранулярный контроль через команды на естественном языке. В среде Google AI Studio появились инструменты, позволяющие задавать контекст сцены, уникальные профили говорящих и так называемые «режиссерские заметки» (Director's Notes). С помощью встроенных тегов можно менять темп, тон и акцент прямо посреди предложения. Это позволяет ИИ-персонажам оставаться в своей роли и естественно взаимодействовать в многоголосых диалогах.
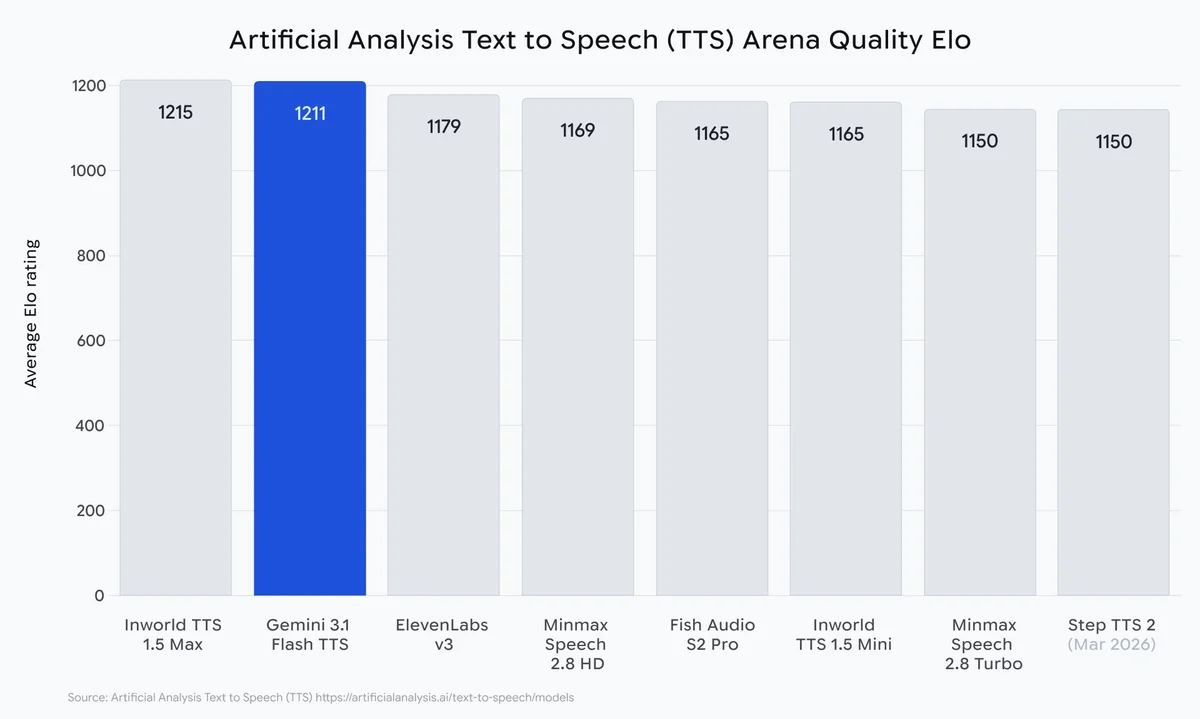
Модель поддерживает более 70 языков, что делает ее инструментом глобального масштаба. По данным независимого бенчмарка Artificial Analysis, который собирает тысячи слепых тестирований пользователями, Gemini 3.1 Flash TTS получила рейтинг Elo 1211. Аналитики отмечают удачный баланс между высоким качеством генерации и низкой стоимостью использования (API).
Важным аспектом релиза стала безопасность. Весь аудиоконтент, сгенерированный с помощью Gemini 3.1 Flash TTS, автоматически помечается невидимым водяным знаком SynthID. Этот алгоритм встраивается непосредственно в аудиосигнал, позволяя надежно определять синтезированную речь и снижая риски распространения дезинформации.
a gif showing artificial analysis text to speech arena quality elo
Модель уже развертывается в нескольких средах: для разработчиков через Gemini API и Google AI Studio, для корпоративных клиентов в Vertex AI, а также для пользователей экосистемы Workspace в приложении Google Vids.
С точки зрения развития индустрии, этот релиз подчеркивает важный сдвиг. Конкуренция в сфере голосового ИИ переходит от базового качества звучания (которое уже достигло высокого уровня у большинства крупных игроков) к инструментам точного управления и интеграции. Возможность зафиксировать идеальное исполнение и экспортировать его параметры в виде кода означает, что компании смогут создавать стабильных и узнаваемых виртуальных дикторов для своих продуктов.
В ближайшей перспективе подобные технологии значительно снизят барьер для создания динамического аудиоконтента. Локализация игр, создание интерактивных обучающих материалов и персонализированных голосовых помощников станут более доступными и качественными процессами.